Ibiyemi Abiodun
« main pageI made a serverless subway tracker
rusttypescriptserverlesscloudflareFebruary 2025

You can check out the subway timetable at mta-trmnl.pages.dev. The source code for this project is on GitHub: frontend, backend.
I am kinda scatterbrained
Every morning, I get up and check the weather and the subway schedule, and then I hop in the shower and immediately forget that information. I get out of the shower, check it again, and then forget again while I’m getting dressed. I search for my phone, unlock it, refresh the weather widget, then refresh the subway widget so many times that my phone disables Face ID and forces me to enter my password. By the time I’m putting my shoes on, I’ve botched the timing and when I get downstairs, it’s 10 minutes until the next train. It’s very annoying.
It seemed like the ideal solution would be something that is always displaying this information, that is always in the same place (in the middle of my apartment), so that the searching and unlocking and forgetting costs less time and attention.
I bought a TRMNL, which is a fancy customizable e-ink display. When I unboxed it and set it up, there was a weather widget, but no MTA widget.
TRMNL has a widget which can take a screenshot of a website and display it on your tablet. I tried pointing it at wheresthefuckingtrain.com, but it didn’t work. WTFT fetches the train data after loading the page itself, but TRMNL’s renderer was returning a screenshot of the page state before any asynchronous requests were made.
So I decided to write my own MTA schedule website (how hard can it be?). I recently learned about Cloudflare’s Durable Objects from a YouTube video, and I was happy to have an excuse to play with them.
In short, a Durable Object is a special type of serverless function that has persistent storage attached to it. It also has alarms, which are timers that are useful for running periodic tasks.
Static Timetables
The MTA publishes subway timetables as mostly GTFS-compliant data. GTFS (General Transit Feed Specification) splits data into the static timetable and the real-time feed.
The static timetable is a ZIP file containing a bunch of CSV files that list out scheduled routes, stop times, route metadata, etc.
❯ wget https://rrgtfsfeeds.s3.amazonaws.com/gtfs_supplemented.zip
❯ unzip gtfs_supplemented.zip
❯ ls -lh
total 155M
-rw-r--r-- 1 ibiyemi ibiyemi 162 Feb 21 19:25 agency.txt
-rw-r--r-- 1 ibiyemi ibiyemi 4.8K Feb 21 19:25 calendar.txt
-rw-r--r-- 1 ibiyemi ibiyemi 17K Feb 21 19:25 calendar_dates.txt
-rw-r--r-- 1 ibiyemi ibiyemi 18M Feb 21 19:25 gtfs_supplemented.zip
-rw-r--r-- 1 ibiyemi ibiyemi 12K Feb 21 19:25 routes.txt
-rw-r--r-- 1 ibiyemi ibiyemi 5.6M Feb 21 19:25 shapes.txt
-rw-r--r-- 1 ibiyemi ibiyemi 126M Feb 21 19:25 stop_times.txt
-rw-r--r-- 1 ibiyemi ibiyemi 63K Feb 21 19:25 stops.txt
-rw-r--r-- 1 ibiyemi ibiyemi 8.4K Feb 21 19:25 transfers.txt
-rw-r--r-- 1 ibiyemi ibiyemi 5.4M Feb 21 19:25 trips.txtOne of these files is much larger than the others. I’m sure that won’t cause any problems.
I whipped up an Astro site that downloads the ZIP file,
unzips it, constructs a bunch of Maps based on the data in the tables, and
then renders the page.
import { parse } from "csv-parse/sync";
import { Temporal } from "temporal-polyfill";
import yauzl from "yauzl";
// see GitHub for full type definitions
// https://github.com/laptou/mta-trmnl/blob/b2f547e89ace6fab34cd4db0e554ecf5354c5998/src/util/mta/index.ts#L13
export interface MtaState {
calendar: CalendarEntry[];
calendarDates: CalendarDateEntry[];
routes: Route[];
stopTimes: StopTime[];
stops: Stop[];
transfers: Transfer[];
lastUpdated: Date;
// Derived data
stations: Map<string, Station>;
lineToStations: Map<string, Set<string>>;
}
async function readZipEntries(
zip: yauzl.ZipFile,
): Promise<Map<string, string>> {
// helper fn which returns a map from zip
// entry filenames to file contents
}
export const MTA_SUPPLEMENTED_GTFS_STATIC_URL =
"https://rrgtfsfeeds.s3.amazonaws.com/gtfs_supplemented.zip";
export async function loadMtaBaselineState(zipPath: string): Promise<MtaState> {
const gtfsData = await fetch(zipPath).then((res) => res.arrayBuffer());
// zipFromBuffer is helper fn omitted for brevity
const gtfsArchive = await zipFromBuffer(Buffer.from(gtfsData), {
lazyEntries: true,
});
const entries = await readZipEntries(gtfsArchive);
// [parse all of the CSV files into arrays of objects]
const stations = new Map<string, Station>();
const lineToStations = new Map<string, Set<string>>();
for (const stop of stops) {
if (!stop.parent_station) {
// process stops into stations and add to mapping
// stations are top-level stops, and
// also have information about which lines service them
}
}
for (const route of routes) {
// create mapping from routes to stations
// so we can efficiently get all of the stations for a given route
}
return {
calendar,
calendarDates,
routes,
stopTimes,
stops,
transfers,
lastUpdated: new Date(),
stations,
lineToStations,
};
}
export function getAllLines(state: MtaState): Route[] {
return state.routes;
}
export function getStationsForLine(state: MtaState, lineId: string): Station[] {
const stationIds = state.lineToStations.get(lineId) || new Set();
return Array.from(stationIds)
.map((id) => state.stations.get(id))
.filter((station): station is Station => station !== undefined);
}
export function getUpcomingArrivals(
state: MtaState,
stationId: string,
limit = 10,
): TrainArrival[] {
// ...
}This worked, but it was incredibly slow, even for development. Astro is designed to be stateless, which means that there’s no way to just load the timetables into memory once and then query the data on subsequent requests. It would reload the entire thing from the beginning every time I made a request, which would take an entire minute.
❯ bun dev
$ astro dev
astro v5.3.0 ready in 157 ms
┃ Local http://localhost:4321/
┃ Network use --host to expose
20:20:12 watching for file changes...
20:21:21 [200] / 69834ms
20:22:30 [200] / 60981msThis is where the Durable Object becomes very useful - I can use it to cache the data!
I tried to define the Durable Object in the same codebase as my Astro site, but that didn’t work for some reason, so I made a separate project. My Astro site can query the Durable Object (DO) over HTTP when it wants to render something, and the DO can read from its cache, only updating the timetables once an hour or so.
DOs can have either key-value storage or SQLite storage. SQLite is perfect for
my use-case because I have a bunch of relational data, so I went with that. I
set up my Durable Object in a very similar fashion, except that instead of
putting the data into Maps, I had it write the data into the rows of my DO’s
SQLite database.
export class MtaStateObject extends DurableObject {
sql: SqlStorage;
constructor(state: DurableObjectState, env: Env) {
super(state, env);
// Get the SQL storage interface.
this.sql = state.storage.sql;
state.blockConcurrencyWhile(async () => {
await this.initializeDatabase();
await this.loadGtfsStatic();
});
}
private async initializeDatabase() {
this.sql.exec(`
CREATE TABLE IF NOT EXISTS calendar (
service_id TEXT PRIMARY KEY,
monday INTEGER,
tuesday INTEGER,
wednesday INTEGER,
thursday INTEGER,
friday INTEGER,
saturday INTEGER,
sunday INTEGER,
start_date TEXT,
end_date TEXT
);
# CREATE TABLE statements for the other tables go here
CREATE INDEX IF NOT EXISTS idx_stop_times_stop_id ON stop_times(stop_id);
CREATE INDEX IF NOT EXISTS idx_trips_route_id ON trips(route_id);
CREATE INDEX IF NOT EXISTS idx_stops_parent_station ON stops(parent_station);
CREATE TABLE IF NOT EXISTS metadata (
key TEXT PRIMARY KEY,
value TEXT
);
`);
}
async fetch(request: Request): Promise<Response> {
const url = new URL(request.url);
let response: Response;
switch (url.pathname) {
case "/lines":
response = await this.handleGetAllLines();
break;
case "/stations":
response = await this.handleGetStationsForLine(url.searchParams);
break;
case "/station":
response = await this.handleGetStation(url.searchParams);
break;
case "/arrivals":
response = await this.handleGetUpcomingArrivals(url.searchParams);
break;
default:
response = new Response("Not found", { status: 404 });
}
return response;
}
/**
* Loads data from the GTFS zip file into SQL.
*/
private async shouldUpdateGtfs(): Promise<boolean> {
// look up last_gtfs_update key in metadata table
// if it's more than an hour ago, return true
}
async loadGtfsStatic() {
if (!(await this.shouldUpdateGtfs())) {
console.log("not updating static gtfs");
return;
}
console.log("updating static gtfs");
try {
const gtfsResponse = await fetch(MTA_SUPPLEMENTED_GTFS_STATIC_URL);
const buf = Buffer.from(await gtfsResponse.arrayBuffer());
const gtfsArchive = await zipFromBuffer(buf, { lazyEntries: true });
// processZipEntries is updated to return a
// map of streams instead of a map of text
const entries = processZipEntries(gtfsArchive);
for await (const [fileName, stream] of entries) {
const parser = parse({
columns: true,
skip_empty_lines: true,
});
stream.pipe(parser);
console.log(`processing ${fileName}`);
switch (fileName) {
case "calendar.txt":
for await (const entry of parser) {
this.sql.exec(
`INSERT OR REPLACE INTO calendar
(service_id, monday, tuesday, wednesday, thursday, friday, saturday, sunday, start_date, end_date)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)`,
entry.service_id,
Number.parseInt(entry.monday, 10),
Number.parseInt(entry.tuesday, 10),
Number.parseInt(entry.wednesday, 10),
Number.parseInt(entry.thursday, 10),
Number.parseInt(entry.friday, 10),
Number.parseInt(entry.saturday, 10),
Number.parseInt(entry.sunday, 10),
entry.start_date,
entry.end_date,
);
}
break;
// insert statements for other tables go here
}
}
// Update the last update timestamp
const now = Temporal.Now.instant();
this.sql.exec(
"INSERT OR REPLACE INTO metadata (key, value) VALUES (?, ?)",
"last_gtfs_update",
now.toString(),
);
} catch (err) {
console.error(err);
throw err instanceof Error ? err : new Error(String(err));
}
}
/**
* Returns all lines (routes).
*/
async handleGetAllLines(): Promise<Response> {
// ...
}
/**
* Returns stations for a given line id.
* Uses the trips table to find trips for the route and then all distinct stops.
*/
async handleGetStationsForLine(params: URLSearchParams): Promise<Response> {
// ...
}
/**
* Returns the station details for a given stationId.
*/
async handleGetStation(params: URLSearchParams): Promise<Response> {
// ...
}
/**
* Returns upcoming arrivals for a given station.
* Requires stationId, an optional direction (north or south),
* and an optional limit (default to 10).
*/
async handleGetUpcomingArrivals(params: URLSearchParams): Promise<Response> {
// ...
}
/**
* Checks if a given service (by service_id) is active today.
* Converts stored strings (YYYYMMDD) to Temporal.PlainDate for comparisons.
*/
async isServiceActiveToday(serviceId: string): Promise<boolean> {
// ...
}
}Then I updated my Astro site to fetch from the DO, and it worked. It was still very slow on the initial request (as the DO fills the database), but every subsequent request would be fast for about an hour. Mission complete? I uploaded my DO to Cloudflare to test it.

Aw, man.
Okay, let’s see how we can bring this CPU time down. What’s taking so long,
anyway? I add console.log() to the database initializer.
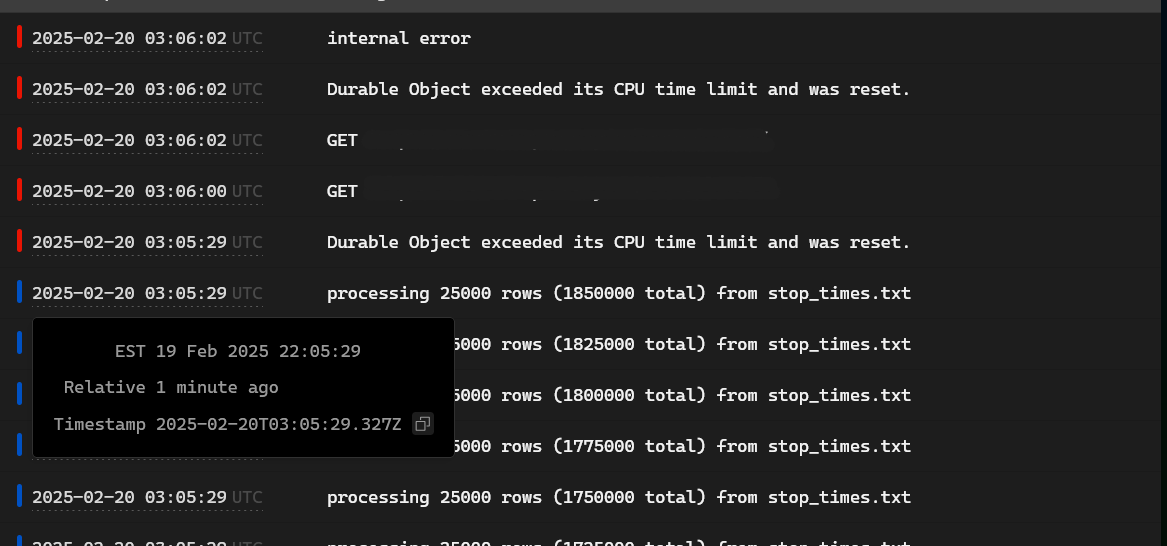
I see. Apparently, the stop_times table (which lists every stop throughout the day for every train on every type of route) contains 2.2 million rows.
Well, SQLite is supposed to be super speedy, so the culprit is probably the fact that we have to read these rows from a ZIP file. Let’s see if we can get the decompression to run faster.
I tried swapping out yauzl for fflate, but no luck. What if we use WebAssembly? I spin up a simple wasm-pack project, add zip and csv, and I’m done.
#[wasm_bindgen]
pub fn unpack_csv_archive(
data: Uint8Array,
row_chunk_len: usize,
callback: Function,
) -> Result<(), wasm_bindgen::JsError> {
// calls unpack_csv_archive_inner after converting the arguments
Ok(())
}
pub fn unpack_csv_archive_inner<
F: FnMut(&str, &js_sys::Array, &js_sys::Array) -> anyhow::Result<()>,
>(
buf: &[u8],
row_chunk_len: usize,
mut callback: F,
) -> anyhow::Result<()> {
let mut ar = zip::ZipArchive::new(Cursor::new(buf)).context("could not create zip archive")?;
for i in 0..ar.len() {
let file = ar
.by_index(i)
.with_context(|| format!("could not open file at index {i}"))?;
let file_name = file.name().to_owned();
let mut reader = csv::ReaderBuilder::new().from_reader(file);
let headers = reader.headers()?;
let headers_arr: js_sys::Array = headers.iter().map(JsString::from_str).try_collect()?;
let mut chunk = vec![];
for record in reader.into_records() {
let record = record?;
let record_arr: js_sys::Array = record.iter().map(JsString::from_str).try_collect()?;
chunk.push(record_arr);
if chunk.len() >= row_chunk_len {
// our callback is written in JS
// it contains a for..of loop that
// inserts all of the rows we just grabbed
callback(&file_name, &headers_arr, &js_sys::Array::from_iter(chunk))?;
chunk = vec![];
}
}
if chunk.len() > 0 {
callback(&file_name, &headers_arr, &js_sys::Array::from_iter(chunk))?;
}
}
Ok(())
}It’s faster, but not by enough.
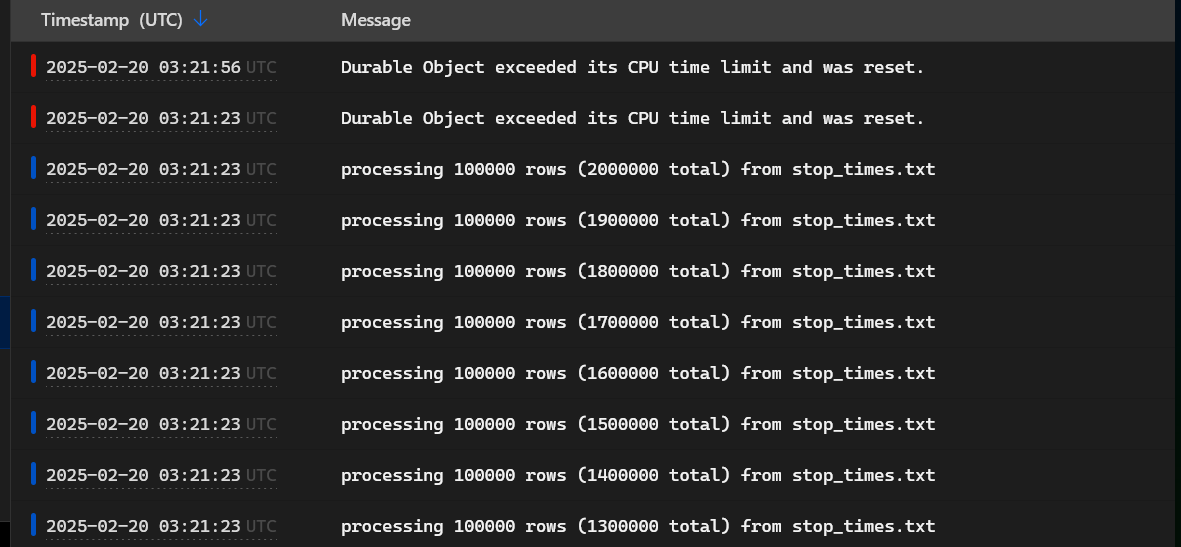
Looks like it’s time to stop guessing based on intuition and do some profiling.
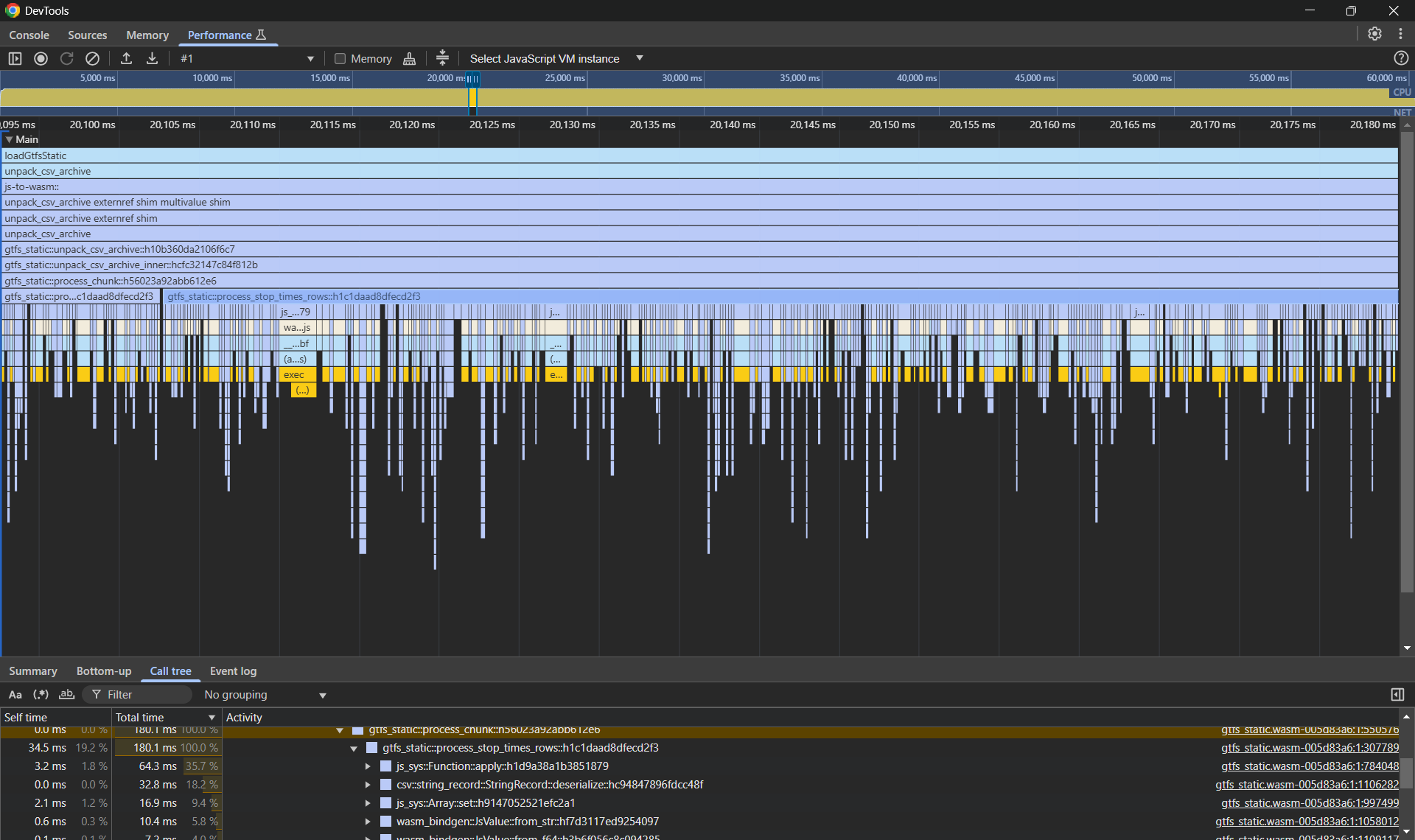
Profiling reveals that the biggest chunks of the execution time are spent in
js_sys::function::apply (that’s our SQL exec() callback) and in csv’s
Deserialize implementation. How can we make our SQLite insertions faster? We
use transactions.
The code is currently designed to insert the rows in chunks of 50,000 rows at a
time. I wrap each chunk in a call to
ctx.storage.transaction(),
and run it again.
Locally, the previous implementation took about 23 seconds to populate the database when running Wrangler locally. After adding transactions, the database populated and the worker returned a response in 4 seconds!
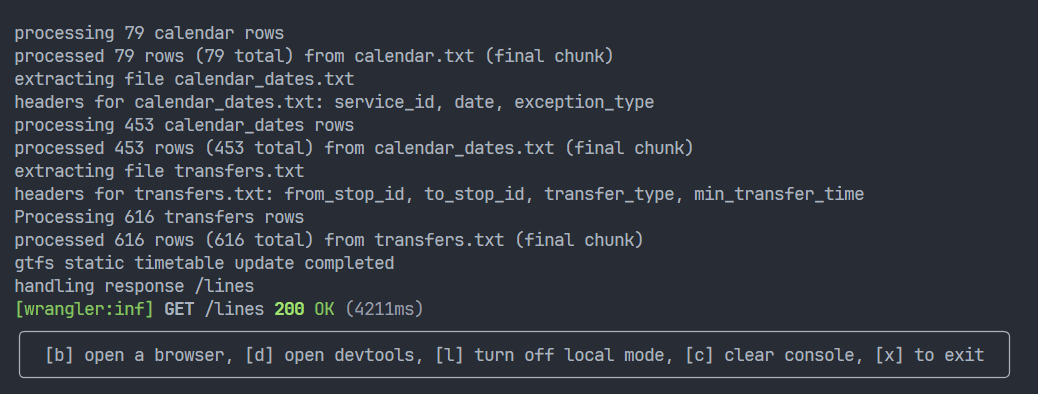
I deploy the new version to Cloudflare, and it works!
We now have a Durable Object that is essentially an on-demand indexed read replica of the current MTA schedule. Nice.
Real-time Updates
This project wouldn’t be complete without real-time updates. The subways are only on time about 80% of the time on average. The unfortunate souls who live next to the F train had to deal with a train that was only on time 64% of the time in December.
So a website that simply shows the schedule without showing current information about the actual trains is worse than useless, because it might lead you to go and stand in a subway station for 30 minutes when you should have just taken a Citi Bike.
GTFS real-time feeds are delivered in Protobuf format. The name “real-time” made me initially expect that it would be streaming responses over a long-lived socket connection, but it’s actually just HTTP polling.
The real-time feeds are pretty straight forward: they contain a list of messages about the current status of the system. This includes messages updated arrival and departure times for a certain route at a certain stop. After parsing the real-time feeds, I simply overwrite the arrival and departure times from the static timetable with the updated ones.
type RealtimeStatusGroup =
| "ACE"
| "BDFM"
| "G"
| "JZ"
| "NQRW"
| "L"
| "1234567"
| "SIR";
async getRealtimeStatus(group: RealtimeStatusGroup): Promise<FeedMessage> {
let endpoint: string;
switch (group) {
case "ACE":
endpoint =
"https://api-endpoint.mta.info/Dataservice/mtagtfsfeeds/nyct%2Fgtfs-ace";
break;
// MTA splits real-time updates into 7 different feeds
// for reasons that are unknown to me
}
const response = await fetch(new Request(endpoint));
// FeedMessage is a class I generated from the GTFS realtime
// protobuf header using @protobuf-ts/plugin
return FeedMessage.fromBinary(await response.bytes());
}
async updateRealtimeStatus(group: RealtimeStatusGroup) {
const status = await this.getRealtimeStatus(group);
const activeServices = await this.getActiveServiceIds();
await this.ctx.storage.transaction(async () => {
for (const msg of status.entity) {
if (msg.tripUpdate) {
if (!msg.tripUpdate.trip) {
console.warn("got trip update without trip", msg);
continue;
}
// MTA identifies trips in realtime feed with a trip ID suffix, like
// "082500_A..N54R". update the trips with active service
const tripIdSuffix = msg.tripUpdate.trip.tripId;
const tripIds = this.sql
.exec<{ trip_id: string; service_id: string }>(
"SELECT trip_id, service_id FROM trips WHERE trip_id LIKE $1",
`%${tripIdSuffix}`,
)
.toArray()
.filter((r) => activeServices.includes(r.service_id))
.map((r) => r.trip_id);
const zeroTime = Temporal.PlainTime.from("00:00:00");
for (const stopTimeUpdate of msg.tripUpdate!.stopTimeUpdate) {
if (!stopTimeUpdate.stopId) continue;
// this is pretty ugly -- Temporal API is very verbose
// esp when interacting with systems that don't use it, but it
// also makes serialization & arithmetic with dates, times,
// datetimes, and durations much easier :D
const newArrival = stopTimeUpdate.arrival?.time
? Temporal.Instant.fromEpochSeconds(
Number(stopTimeUpdate.arrival.time),
)
.toZonedDateTime({
timeZone: "America/New_York",
calendar: "gregory",
})
.toPlainTime()
.since(zeroTime)
.total("seconds") | 0
: null;
const newDeparture = /* ... */;
this.sql.exec(
`
UPDATE stop_times
SET arrival_total_seconds = IFNULL($1, arrival_total_seconds),
departure_total_seconds = IFNULL($2, departure_total_seconds),
is_realtime_updated = 1
WHERE trip_id IN (${tripIds.map((t) => `"${t}"`).join(",")}) AND stop_id == $4
`,
newArrival,
newDeparture,
stopTimeUpdate.stopId,
);
}
}
}
});
console.log("updated realtime status for ", group);
}An accidental discovery
Once I got code that was working, I started cleaning up my code. While I was
doing so, I noticed that Durable Objects actually have two methods for
creating transactions: transaction and transactionSync. I was calling
transaction in my stop_times loader, which has the signature transaction(cb: () => Promise<void>): Promise<void>.
This is not so ideal because:
- My callback doesn’t actually return a
Promise. Even though my code seems to be working for now, Cloudflare could later decide this is an error, or it could trigger some sort of subtle bug that will drive me crazy later. - Error propagation is broken. If the promise returned by
transactionrejects, this would be silently ignored, which could also drive me crazy by making it hard to troubleshoot any bugs in the loading process.
So I tried swapping it out for transactionSync and the loader went back to being unusably slow!
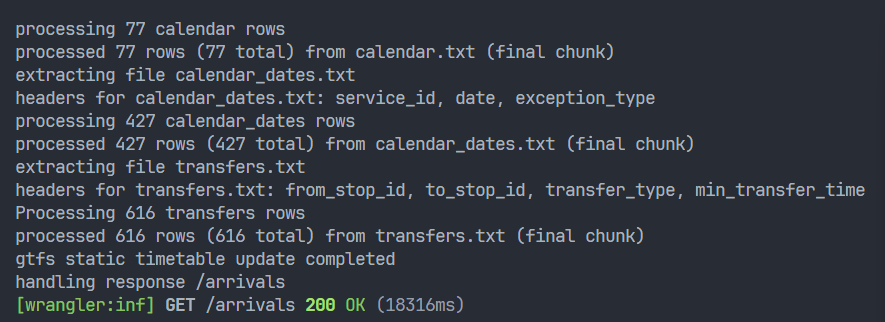
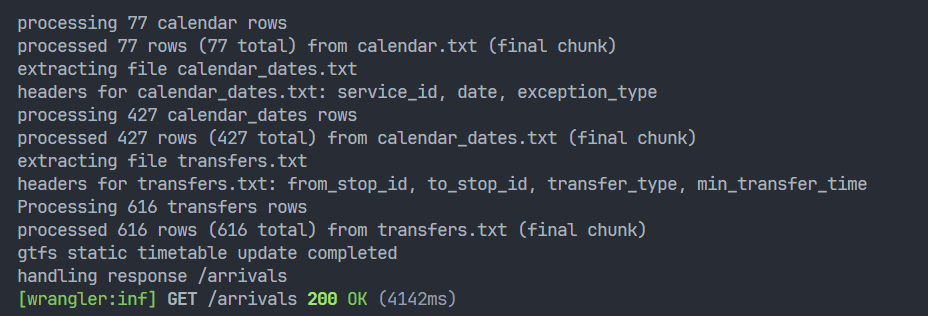
My hunch is that by spamming a bunch of calls to transaction, I was
accidentally pipelining my writes.
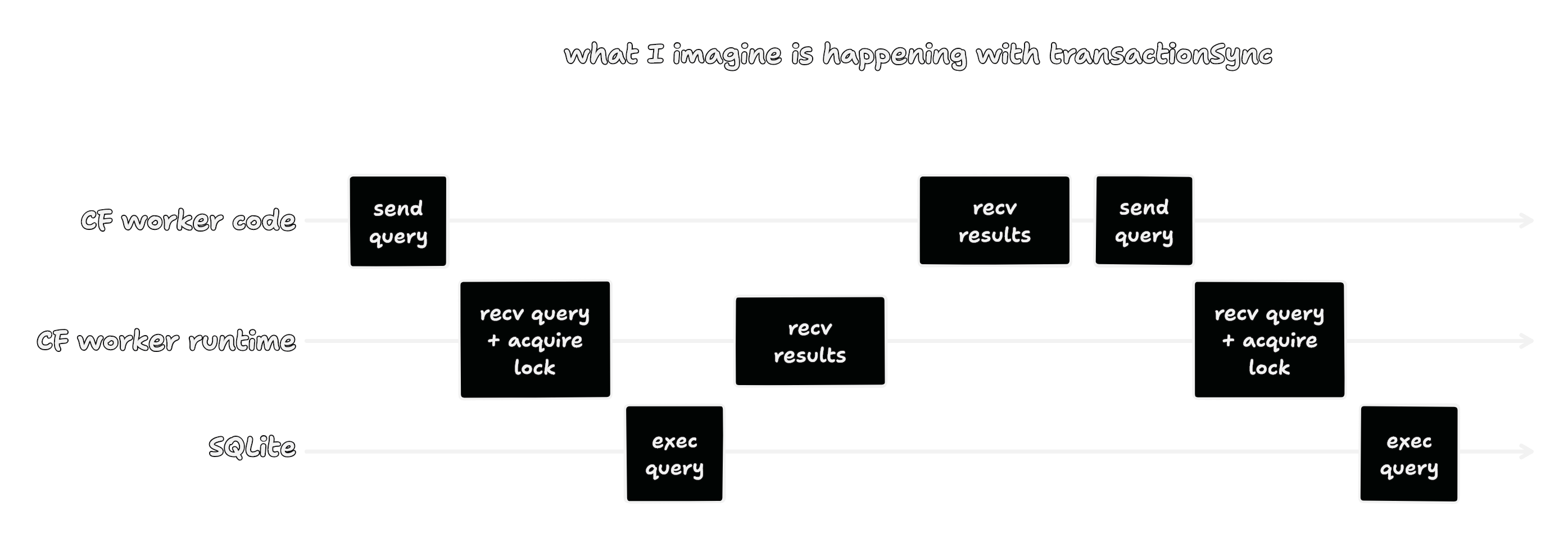
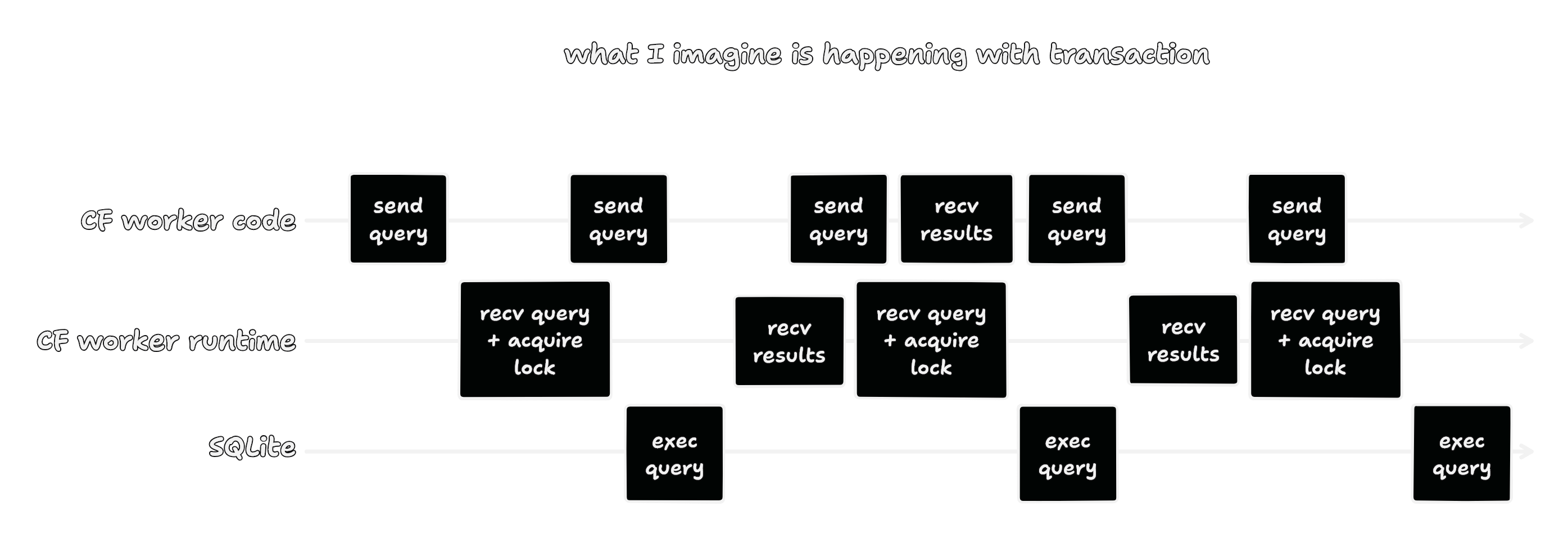
Even though this code doesn’t have great stability properties for the reasons I described, this is a random side project with nothing on the line. Therefore, I have decided that it is not a “hack”, but instead it is an “optimization” :)
If I wanted to use this technique in a real project, I would probably round up
all of the Promises and do a Promise.all for error propagation.
Conclusion
It would have been easier to put this project on my Coolify instance in the cloud. There are no specific CPU time limits there. This also would have enabled me to use MTAPI. But I wanted to learn about Durable Objects. If I had done it the normal way, I wouldn’t have learned anything new, and I would have just created a subway timetable instead of a highly-optimized Web Scale™️ serverless on-demand fault-tolerant 99.9% available subway timetable.
My favorite feature of Durable Objects is their alarms. I have found that scheduling tasks in a distributed/serverless environment is usually extremely annoying and tends to nudge you towards setting up a dedicated job queue. I like that alarms are very easy to use and require nearly zero additional effort.
You can check out the subway timetable at mta-trmnl.pages.dev.
The source code for this project is on GitHub: frontend, backend.